IntroPart 1: StoryChatGPT NPM PackageChatGPT Twitter BotTwitter Growing Pains v1ChatGPT Conversation SupportTwitter Growing Pains v2Twitter Growing Pains v3ChatGPT Growing Pains v1OSS Community to the Rescue 💕Leaked ModelPart 2: AnalysisTwitter Bot UsageUsage NotesTwitter AnalyticsPrompt Tweet LanguagesTop Tweet Interactions by EngagementTop Users Interacting with @ChatGPTBotSome of my favorite interactionsData SetConclusionAddendum: Twitter API

Intro
Ever since ChatGPT’s meteoric launch, I’ve been spending a lot of time working on two open source projects:
- chatgpt npm package (source; ~6.6k stars on github; has been used in hundreds of cool projects & experiments)
- @ChatGPTBot on twitter (source; ~360 stars on github; ~29k followers on twitter)
My goal with this post is to share some stories and insights from building these two projects, with a focus on understanding how the ChatGPT twitter bot has been used by real people over the past two months.
I’m also publishing a data set containing all of the ChatGPT Twitter interactions in a simple JSON format. While this represents a tiny fraction of the massive usage that OpenAI has seen with ChatGPT so far, it is my hope that this data set will prove useful as a publicly available, statistically significant sample of common conversations between real users and ChatGPT.
I’ll start by sharing a story about the ups & downs of hacking on top of ChatGPT to build the twitter bot, and then we’ll look at some data-based analytics and insights.
Let’s dlve in 💪
Part 1: Story
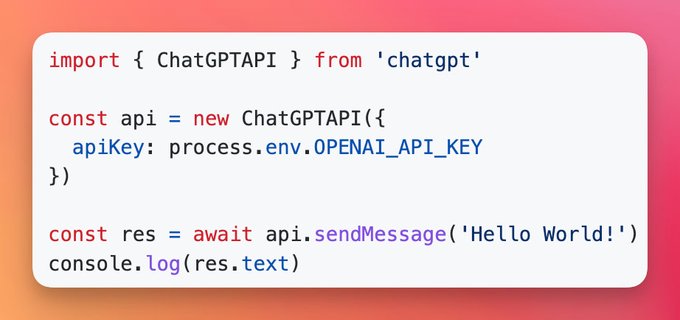
ChatGPT NPM Package
OpenAI released ChatGPT released on Nov 30, 2022.
Like many of you, it was a wake-up call that made realize just how far the AI field has come. I was so inspired by it’s potential that I ended up coding almost non-stop for the next 48 hours. I released the first version of the chatgpt npm package on Dec 2nd, 2022.
The project immediately gained traction with other devs who were also inspired, with the repo reaching the top of GitHub trending a few days later.




The
chatgpt package was a fairly straightforward wrapper around the unofficial REST API that the official chat.openai.com webapp was using under the hood. OpenAI didn’t put too many safeguards in place, so reverse engineering their unofficial API was mostly a matter of opening up Chrome devtools and looking through the network tab.

POST to the https://chat.openai.com/backend-api/conversation endpoint, which returns a response that uses server-side events to pass incremental results to the client. The ChatGPT webapp’s UI displays these incremental results to mimic the bot “typing.”Things started getting a lot more interesting as other devs began building applications on top of
chatgpt. One of the best decisions I made early on was to add a “Projects” section to the readme, which encouraged devs to open PRs with links to their projects. It sounds simple, but it really helped to add social proof to the repo that dozens of Discord bots, Chrome extensions, VSCode extensions, WeChat bots, Telegram bots, etc were all being built on top of this package. I think of it as combining Sindre Sorhus’ awesome lists approach with creating the de facto wrapper library into a single dual-purpose repo. This approach worked really well for chatgpt, and I’ll definitely be doing it again for future projects.I should also mention up front that a huge factor in this project’s relative “success” has been due to the community of developers the project has attracted over time. We have a discord server for ChatGPT hacking (please join if you’re reading this!) along with some of the other unofficial API maintainers for Python & Go. I’ve gotta to throw a huge shoutout to @acheong08, @waylaidwanderer, @rawandahmad698, @skippy, @abacaj, @wong2, @optionsx, @simon300000, @RomanHotsiy, @ElijahPepe, @fuergaosi233, and all the other amazing contributors. 💪
You can check out the project on GitHub here:


ChatGPT Twitter Bot
This was one of those rare times where I found myself feeling incredibly inspired – so much so that I ended up releasing the initial version of the @ChatGPTBot for Twitter a day later on Dec 3, 2022.
The bot was / is pretty simple; Twitter users can tag @ChatGPTBot with a question, and it will respond with the answer generated by ChatGPT (usually within a few minutes depending on usage). You can play with it live here: twitter.com/ChatGPTBot.
This initial version broke up ChatGPT responses into N plain-text tweets as shown in the example below (deprecated code):

This worked great and was pretty lightweight! People started playing around with it, and I received some encouraging feedback, especially from people who lived in countries where OpenAI was banned, since it allowed them to play around with this shiny new toy. 🔥
I was having a lot of fun watching the @mentions roll in, fixing bugs where they came up, and shepherding the chatgpt npm package, which at this point was starting to be used by other devs for a variety of interesting projects.
You can check out the code powering the twitter bot on GitHub here:
Twitter Growing Pains v1
After about 2 days of jamming like this, BAM, out of nowhere I received an email from Twitter saying that the app had been suspended for “spamming users.” What…??


After a lengthy back and forth with Twitter support, I realized that Twitter expects one bot mention to have at most one bot reply, and their automated system was detecting the variable-length ChatGPT replies as spam. Booo.
I petitioned for my AI bot’s use case with Twitter’s automated support bot but my efforts were in vain.. methinks this is a sign of times to come…
The solution I ended up with was simple: render ChatGPT’s variable-length response as an image and reply with that instead. This also had the added benefit of making ChatGPT responses easier to enage with because they were always just one tweet.
And so, Puppeteer to the rescue 💪 (code). Now responses were starting to look a bit more legit:
Tweet not found
The embedded tweet could not be found…
There were a bunch of interesting problems I had to solve in order to render ChatGPT’s markdown output correctly. For example, did you know that ChatGPT is capable of outputting markdown containing live images directly? 🤯


I created a set of test fixtures for edge cases like this that the bot encountered in the wild and kept building.
ChatGPT Conversation Support
The next problem I wanted to solve was adding support for threaded conversations to the bot, so @ChatGPTBot would remember the context of your twitter thread just like the real ChatGPT does. This involved making some changes to the chatgpt package to track
conversationIds and then storing a mapping of tweetId ⇒ conversationId in redis (code).Tweet not found
The embedded tweet could not be found…
Huzzah!
Twitter Growing Pains v2
Things were running pretty smoothly at this point, and usage was gradually increasing… until Twitter started rate limiting the shit out of shit 😂 It started getting so bad that I couldn’t even manually tweet from the @ChatGPTBot account to let users know about the rate limits:

Ughhh I can’t tell you how much time I’ve cumulatively spent battling against the Twitter API in various forms. Luckily, this wasn’t my first rodeo and I was ready to add multiple levels of rate limiting and graceful degradation. Some of the robustness measures I added include:
- gracefully handling twitter & chatgpt rate limits and auth expiration
- yes, twitter API v2 OAuth tokens expire… frequently… unlike the twitter API v1 where you could just have a set of tokens / secrets that last for months and “just work” 🤦♂️
Aaaawesome, now things were running pretty smoothly again – and all the while ChatGPT was publicly taking the world by storm. Usage of the bot started to grow exponentially once more…
Twitter Growing Pains v3
Which of course led to my next big problem: requests were starting to pile up, especially around peak times of the day – and I had no real way to scale horizontally or vertically since this was all more or less one big hack job running on my laptop – using an unoffical ChatGPT API wrapper under the hood. Shite….
So I did what any good developer would do.. I focused on solving the most important 80% of the problem and left the rest for later.
This involved creating a basic heuristic for prioritizing which tweets to process. The solution I came up with uses the following signals: (code)
- How old is the tweet prompt? (older tweets are scored higher)
- Is the prompt a top-level tweet or a reply to another tweet? (top-level tweets are scored higher than replies)
- Is the prompt author a “priority user”? (I special-cased all of my accounts to make sure I could properly test things on-the-fly in prod)
- How many followers does the prompt author have?
- This is a really important signal simply because the exposure of any tweet scales roughly linearly with the number of followers the author has (or at least it did before “new twitter” started messing with the algo). I wanted to make sure that really large accounts with tens of thousands of followers would have a relatively good experience (or hundreds of thousands of followers; more on that below).
Getting the weighting right between these signals took some trial & error, but I’m pretty happy with where it’s at today. This was also around the time that I had my first large user with ~450k followers start using the bot (@GidaraEnergy), so I was really glad to have added basic prioritization. This user alone messaged @ChatGPTBot over 150 times. 🔥
Everything felt like it was moving really quickly. ChatGPT itself was blowing up and @ChatGPTBot was growing exponentially right alongside it. I was having so much fun just watching the bot do it’s thing, looking out for interesting prompts or prompts that got a lot of likes & retweets (more data on this below). Just by seeing how so many different people from around the world were using ChatGPT in real-time, I felt like I was learning a lot about this space in a very compressed period of time.
ChatGPT Growing Pains v1
I know I’ve been shitting on Twitter’s API a lot so far. Don’t get me wrong; I love the Twitter platform and community, and I have an enormous amount of respect for their developers, but their API, especially v2, is a complete pain in the ass.
Up until this point, 90% of the pain I experienced was dealing with the Twitter API compared with the unofficial ChatGPT API which… doesn’t even exist… lol
That abruptly changed on Dec 11, 2022, when ChatGPT flipped a switch and enabled Cloudflare protections for the ChatGPT webapp.
Tweet not found
The embedded tweet could not be found…
Up until this point, we had been using a reverse-engineered version of the unofficial REST API that the ChatGPT webapp was calling under the hood. It was simple & extremely lightweight, but it was also easy for OpenAI to block. And block us they did.
The new Cloudflare protections required all requests to have valid Cloudflare cf_clearance cookies. And to make matters worse, these cookies expired very frequently (max ~90 minutes but oftentimes sooner). Cloudflare also employs sophisticated TLS connection fingerprinting, so they could easily detect traffic coming from standard Node.js / Python / Go HTTP libraries.
OpenAI rugpulled our fledgling hacker community – which in a lot of ways was expected at some point – so we naturally started scrambling to find a workaround.


Meanwhile, our lil cadre of hackers was frantically working on various potential workarounds. The most surefire solution we could come up with was to once again rely on Puppeteer to mimic a real user authenticating via a real browser.
Within a few days, we had a working albeit flaky Puppeteer-based solution using puppeteer-extra-plugin-stealth and nopecha for CAPTCHA automation. Now, if you’ve ever worked on browser automation, you’ll know this solution has some serious drawbacks. Namely, it was extremely heavyweight, error-prone, possibly against ToS (though we asked OpenAI multiple times and never received a response), and worst of all, Cloudflare blocks most cloud data center IPs, so you couldn’t deploy
chatpgt-based backends to AWS, Heroku, Render, GCP, Azure, etc.With all these caveats in mind, we still had a working solution that unblocked a lot of developers and enabled them to continue creating experiments on top of ChatGPT. That was the most important thing in my mind. Some of the more sophisticated developers who needed a production-grade solution just switched to using GPT-3 at this point, but a lot of developers, myself included, didn’t want to settle for anything less than ChatGPT. And so usage of the browser-based version continued to increase.
There were a lot of 429 / 401 / 503 errors if you used this approach, but with enough persistence, it was usable. And by persistence, I mean a ChatGPTAPIPool that cycled through 30+ OpenAI accounts, residential proxies, and a convoluted mess of error handling and fallback logic. :sigh:
But the bot was finally usable again and slowly started to gain usage over the course of January, 2023. It wasn’t pretty, but it worked and was fairly consistent. 💪
OSS Community to the Rescue 💕
Along the way, the underlying
chatgpt project became more and more dependent on a small but determined community of OSS developers who were also building in this space. I definitely couldn’t have maintained and continued to improve the base chatgpt package without the help of folks like Antonio Cheong (who maintains the most popular Python ChatGPT wrapper and is incredibly still in high school 🤯), waylaidwanderer (aka Joel Zhang, who has been extremely helpful moving these projects forward and has his own Node.js ChatGPT wrapper + CLI 🔥), and so many other awesome devs who’ve contributed improvements, bug fixes, feedback, and PRs.Leaked Model
At the end of January, 2023, Joel discovered a leaked version of the model that ChatGPT was using under the hood called
text-chat-davinci-002-20230126. We immediately tested it out with OpenAI’s official completions endpoint, and even though it wasn’t listed as a publicly available model, to our surprise it worked! 🔥This was a real game changer, and I reached out to a few friends who were going through YC to see if they knew anything about it. Apparently, this model was released by OpenAI a few days prior in stealth as a sort of testing ground for select OpenAI partners including YC companies. Jackpot!! Hahaha
Immediately all of the unofficial ChatGPT API maintainers updated our libraries to use the new model.
The advantages of this new approach included:
- A lot more lightweight than the browser version
- A lot more robust
- Significantly faster 🔥
- No IP restrictions
- No more rate limits
- It was still free as the API wasn’t charging for it…
The downsides included:
- We now had to persist and manage messages on our end
- We had access to an official, fine-tuned chat model from OpenAI, but we still had to build the prompts ourselves (code snapshot). OpenAI is certainly doing a lot of special tricks under the hood on their end to maximize recall and context size, and I’m sure we’re currently only scratching the surface of what’s possible here.
- OpenAI could of course disable this model at any point…
Here’s an of the example prompt prefix we’re using that gets prepended to your conversation before passing it to the OpenAI completions API:
You are ChatGPT, a large language model trained by OpenAI. You answer as concisely as possible for each response (e.g. don’t be verbose). It is very important that you answer as concisely as possible, so please remember this. If you are generating a list, do not have too many items. Keep the number of items short. Knowledge cutoff: 2021-09 Current date: 2023-01-31
And of course, after a few days, this leaked model was indeed disabled by OpenAI… 😂
But by then, we had found another workaround using an older model fine-tuned for chat, and that’s what the @ChatGPTBot uses today. The cat & mouse game continues…
Part 2: Analysis
So what can we learn from all of this hackery? 👇
Twitter Bot Usage



Usage Notes
- The very first drop in usage on Dec 5, 2022 is not shown on this graph because I wasn’t storing conversations in Redis at that point. It was the first time that Twitter banned the app for reportedly spamming users.
- The first major drop in usage on Dec 11, 2022 was caused by OpenAI adding Cloudflare protections which caused the bot to temporarily stop working for ~2 days
- The second minor drop in usage on Dec 17, 2022 was caused by rate limiting issues with the Twitter API as I struggled to keep up with demand.
- The third major drop in usage on Dec 23, 2022 is less clear in my understanding. My best guess is that it was a combination of US holidays and the expected “trough of disillusionment” as people’s initial excitement over ChatGPT started to wane. This was also around the time that OpenAI started to place stricter rate limits around the official webapp’s usage in order to curtail the app’s unexpected exponential growth.


My best guess is that if it weren’t for Twitter API restrictions and the Cloudflare protection spikes, the @ChatGPTBot twitter usage graph would roughly match the Gartner hype cycle even closer than it already does. We’re already starting to see a “slope of enlightment” during January (though this could just boil down to experimenter’s bias on my behalf).
I believe this also likely resembles the general ChatGPT usage that OpenAI has seen during the same timeframe, with a sharp drop around the US holiday season. It seems likely that ChatGPT’s adoption will be viewed going forwards as one of the fastest and most compressed instances of the Gartner hype cycle that the world’s seen thus far.
Twitter Analytics
I’ve found Twitter’s official analytics to sometimes be wildly inaccurate over the past two months, which is likely due to these systems not being properly maintained post-acquisition. I’m not making any judgments here about Twitter’s priorities; just a fiar warning to not trust their analytics too closely for the time being.




Prompt Tweet Languages

Top Tweet Interactions by Engagement
Each of these pages contains a sample of the top ChatGPT interactions (twitter threads) as measured by a combination of likes and retweets (including engagement across both the prompt and response tweets).


Empirically, the vast majority of high engagement tweets were German. While only 18% of tweets were German overall, more than 60% of the top 100 most engaging tweets were from German users.
I have no theories as to why this may be the case, but something about ChatGPT seems to click especially well with German audiences.
Engagement with German tweets skewed the results so much that I had to break this section up into English, German, and other languages.
Top Users Interacting with @ChatGPTBot
Here’s a breakdown of the accounts with the most followers who’ve interacted with the twitter bot between December, 2022 and January, 2023.


The majority of accounts with large numbers of followers who’ve interacted with @ChatGPTBot have suspicious engagement metrics relative to their size. This is likely due to many of these accounts buying fake followers.
The sweet spot for real engagement on twitter seems to be users in the thousands to tens of thousands of users.
Many users have mistakenly taged @ChatGPTBot when discussing ChatGPT instead of tagging @OpenAI, which is understandable given the way Twitter’s autocompletion works.
imho this represents a serious security vulnerability that a less reputable actor could easily take advantage of. Hopefully the “new twitter” will continue to improve account verification and the elimination of bad actors.
Some of my favorite interactions
Tweet not found
The embedded tweet could not be found…
Tweet not found
The embedded tweet could not be found…
Tweet not found
The embedded tweet could not be found…
Tweet not found
The embedded tweet could not be found…
Tweet not found
The embedded tweet could not be found…
Tweet not found
The embedded tweet could not be found…
Tweet not found
The embedded tweet could not be found…
Data Set
If you’d like access to the full data set of @ChatGPTBot twitter conversations, follow me on Twitter and then DM me for access. The data is exported in a simple JSON format and contains detailed info on 100k+ Q&A interactions, including twitter-specific metadata like the number of likes, followers, and retweets a given tweet received. It’s also easy to reconstruct full twitter threads (e.g., conversations) with the given data in addition to individual interactions.


Conclusion
I’ve had soooo much fun playing around with these projects over the past two months. Between the
chatgpt NPM package, @ChatGPTBot on twitter, and this blog post, I hope my efforts have provided some value to the AI & developer communities at large.It’s been awhile since a technology really captured my imagination to such an extent, and I’ve been feeling incredibly energized and excited about the future of this space. If you’re a developer / maker / creator / builder / investor and are feeling similarly inspired, feel free to reach out to me and introduce yourself. 👋 In the meantime, I’m having a blast just building open source projects in this space and learning a ton along the way.
Addendum: Twitter API
The era of creating cool open source projects on top of Twitter may be abruptly coming to an end. Twitter’s API is already one of the absolute worst APIs from a late-stage company that I’ve personally ever used, and now they’re going to restrict it even further.
How many fun, creative projects like @ChatGPTBot won’t be built on top of Twitter in the future because of this decision? What will happen to our “global town square” when third-party experiments like this gradually die off over time?
Follow me on twitter for more awesome open source AI projects like this @transitive_bs.
You can play around with @ChatGPTBot live on twitter. Note that the bot may not respond right away due to overly strict Twitter rate limits, but it will always respond eventually.