


This is the first in a series of posts exploring what “open sourcing Twitter’s algorithm” would look like from a more practical perspective.
IntroMotivationHow Twitter WorksMain Timeline ViewCore Data ModelCore Resource ModelsCore Tweet RelationsCore User RelationsTurtles All The Way DownNetwork GraphFeed AlgorithmRanking SignalsAlgorithmic Feed PseudocodeEngineering ConsiderationsScaleReal-TimeReliabilitySecurity & PrivacyConclusion (for now)Further Reading
Intro
As a experienced software engineer with a passion for open source, Elon Musk’s recent appeal to open source the Twitter algorithm inspired me to start researching this space. My goal was to try and answer one main question:
What would open sourcing the Twitter algorithm actually look like?
In order to answer this question, there are some related questions we’ll need to answer first:
- Why would we want to open source the Twitter algorithm?
- What do we mean when talking about the “Twitter algorithm”?
- What does Twitter’s core data model look like?
- What does Twitter’s network graph look like?
- How does Twitter’s algorithmic feed work?
- What are the main engineering challenges that we should keep in mind?
Motivation
What’s behind Elon’s bid to take over Twitter? In his own words:
“Civilizational risk is decreased the more we can increase the trust in Twitter as a public platform.”
Elon’s motivation is clear and consistent with his modus operandi. It’s the same reason he’s working so hard to build a sustainable colony on Mars, why he’s devoted resources to understanding the potential dangers of AI super-intelligence, and why he’s so insistent on combatting climate change.
His guiding motivation is to improve humanity’s chances at a positive future.
And unlike most of us, he’s capable of putting massive skin in the game to get shit done. Whether it be by investing his personal fortune or by investing his vast experience as the world’s most successful serial entrepreneur, it’s really hard to argue with the purity of his goals, dedication, and real-world results.
Elon and Jack both believe that the world would benefit from greater transparency and optionality around Twitter’s core algorithms. There are just too many valid concerns around free speech, censorship, privacy, bot armies, echo chambers, ... the list goes on. These are all so fundamentally difficult and nuanced topics, that the only way to attempt meaningful improvements to them — while maximizing the public’s perception of trust in the platform and in each other — will be to provide more transparency around how they’re handled.
So we’re left with the goal of “open sourcing Twitter’s algorithm,” which sounds really great in theory and may actually benefit Twitter’s core business, but that’s where the conversation starts to get really hand wavy. So let’s draw back the curtains a bit and see if we can add some clarity to this conversation from an engineering perspective.
How Twitter Works
Main Timeline View


Twitter provides users with two versions of its main timeline view: the default algorithmic feed “Home” and “Latest Tweets”. The latest tweets view is a much simpler, reverse-chronological list of tweets from accounts you directly follow. This used to be the default until Twitter introduced its algorithmic feed in 2016.
The algorithmic feed is how most people use Twitter because defaults matter — a lot. Twitter describes their algorithmic feed as follows:
“A stream of Tweets from accounts you have chosen to follow on Twitter, as well as recommendations of other content we think you might be interested in based on accounts you interact with frequently, Tweets you engage with, and more.”
There’s a lot of complexity hiding in that “and more.” We’ll dig deeper on that in a bit, but first let’s understand why Twitter use an algorithmic feed at all. The UX reasoning is simple:
“You follow hundreds of people on Twitter — maybe thousands — and when you open Twitter, it can feel like you’ve missed some of their most important Tweets. Today, we’re excited to share a new timeline feature that helps you catch up on the best Tweets from people you follow.” (source; 2016)
This explanation makes sense from a UX standpoint, and an algorithmic feed certainly gives Twitter a lot more freedom to experiment with the product.
The real motivation, however, is because using an algorithmic feed is incentivized by Twitter’s currrent ad-driven business model. More relevant content in your feed ⇒ higher engagement ⇒ more ad revenue. This is a classic social network strategy that’s proven to work.
Okay, so now that we understand Twitter’s algorithmic feed at a high level, let’s dig deeper to try and understand how it works under the hood.
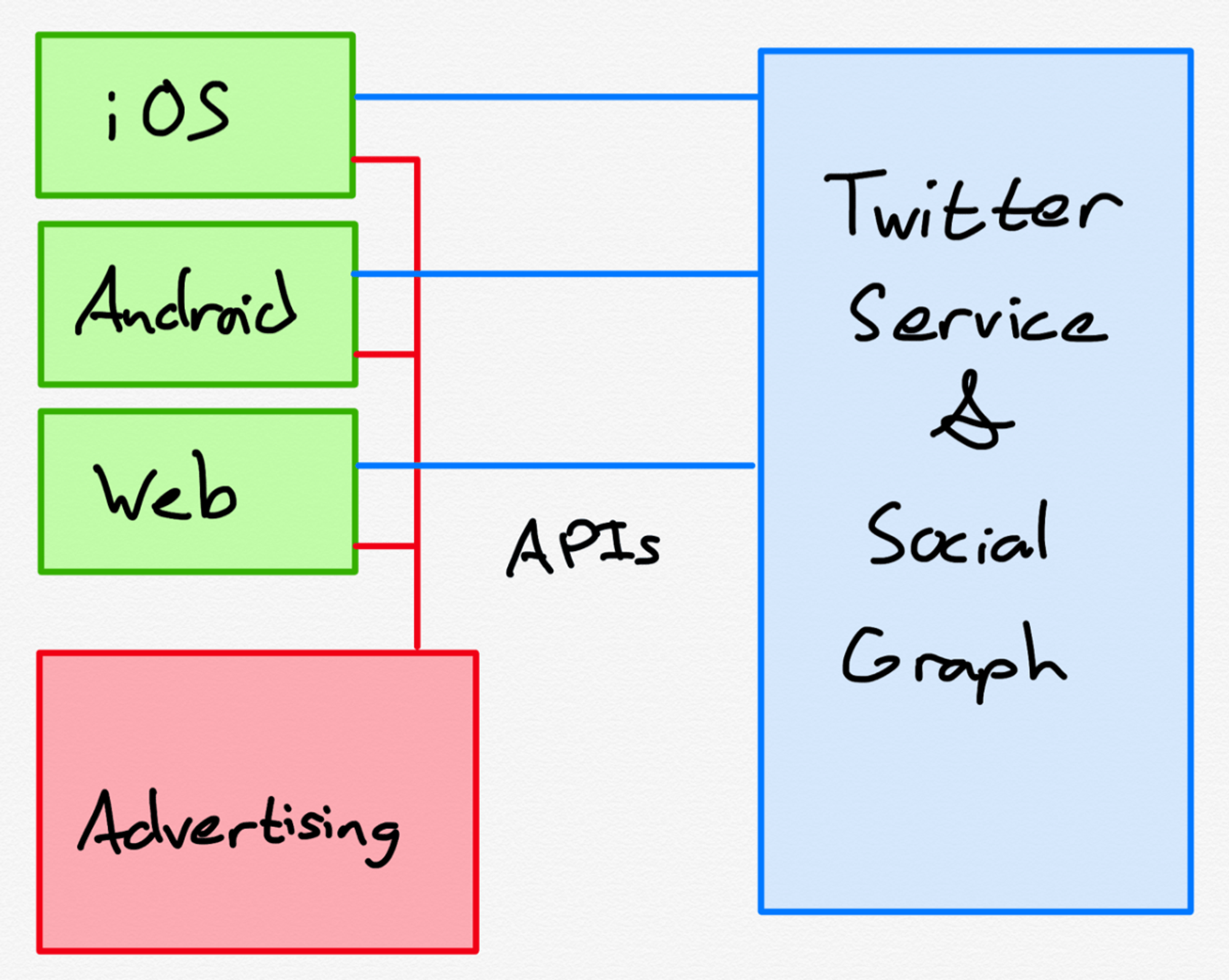
Core Data Model
A great way to approach understanding a complex system like Twitter is to start by understanding its core data model and working our way up from there. These resource models and the relations between them form the foundation that all of Twitter’s higher-level business logic builds upon.
We’ll be focusing on the latest version of Twitter’s public API (v2), which was initially released in 2020.
Core Resource Models
- Tweet — A short post that may reference other tweets, users, entities, and attachments.
- User — An account on the Twitter platform.
Core Tweet Relations
- Timelines — Reverse-chronological stream of tweets from a specific account.
- Likes — Liking tweets is a core user interaction to express interest in a tweet. Note that likes are historically also referred to as favorites.
- Retweets — Retweeting allows you to amplify another user’s tweet to your own audience.
Core User Relations
- Follows — Following a user creates a directed edge in the network graph subscribing you to their tweets and opting in to receiving direct messages from them.
- Blocks — Blocking helps people restrict specific accounts from contacting them, seeing their Tweets, and following them.
- Mutes — Muting an account allows you to remove an account's Tweets from your timeline without unfollowing or blocking that account. Muted accounts will not know that you've muted them and you can unmute them at any time.
Turtles All The Way Down
Twitter’s public API exposes additional resource models (like Space, List, Media, Poll, Place, etc) and additional relations (like Mentions, Quote Tweets, Bookmarks, Hidden Replies, etc). We’re going to ignore these for now in order to keep our exploration as focused as possible.
Keep in mind this is also just the public API. Internally, platforms like Twitter are a complex web of services, databases, caches, workflows, people, and all the glue that holds them together. I have no doubt that Twitter use different abstractions for different layers of their public and internal APIs depending on a variety of factors such as who the API is meant for, performance requirements, privacy requirements, etc. For a brief glimpse into this complexity, check out The Infrastructure Behind Twitter: Scale (2017).
In other words, it’s turtles all the way down and we’re purposefully restricting ourselves to only considering a few turtles — but those other turtles exist, and it’s important to keep that in mind as we move forwards.


Network Graph
Social networks like Twitter are examples of very large-scale graphs, with the nodes modeling users and tweets, and the edges modeling interactions such as replies, retweets, and likes. (source; 2020)


A large part of Twitter’s core business value comes from this massive underlying data set of users, tweets, and interactions. Whenever you log in, view a tweet, click on a tweet, view a user’s profile, post a tweet, reply to a tweet, etc — just about every single interaction you take on Twitter gets logged to an internal database.
The data available from Twitter’s public API represents just a fraction of the data that Twitter tracks under the hood. This is important to keep in mind because Twitter’s internal recomendation algorithms have access to all of this rich interaction data, whereas any open source efforts would likely be required to work with a much more limited data set.



Feed Algorithm
From Using Deep Learning at Scale in Twitter’s Timelines (2017):
“Your timeline composition before the introduction of the ranking algorithm is easy to describe: all the Tweets from the people you follow since your last visit were gathered and shown in reverse-chronological order. Although the concept is simple to grasp, reliably serving this experience to the hundreds of millions of people on Twitter is an enormous infrastructural and operational challenge.
With ranking, we add an extra twist. Right after gathering all Tweets, each is scored by a relevance model. The model’s score predicts how interesting and engaging a Tweet would be specifically to you. A set of highest-scoring Tweets is then shown at the top of your timeline, with the remainder shown directly below.”
Twitter’s algorithmic feed is powered by a personalized recommendation system for predicting which tweets and users you’re most likely to interact with. The two most important aspects of this recommendation system are:
- The underlying data that’s used to train ML models. This is Twitter’s massive, proprietary network graph that we described above.
- The ranking signals that it considers when determining relevancy.
Let’s dive into these ranking signals to understand what Twitter means by “relevancy.”
Ranking Signals
From Using Deep Learning at Scale in Twitter’s Timelines (2017):
“In order to predict whether a particular Tweet would be engaging to you, our models consider characteristics (or features) of:
- The Tweet itself: its recency, presence of media cards (image or video), total interactions (e.g. number of retweets and likes)
- The Tweet’s author: your past interactions with this author, the strength of your connection to them, the origin of your relationship
- You: Tweets you found engaging in the past, how often and how heavily you use Twitter
Our list of considered features and their varied interactions keeps growing, informing our models of ever more nuanced behavior patterns.”
This description of ranking signals from 2017 may be a bit dated, but I have no doubt that these core signals are still highly relevant in 2022. This list has likely expanded to dozens if not hundreds of focused machine learning models that Twitter uses to power its algorithmic feed.


Algorithmic Feed Pseudocode
If you’re a developer, then this TypeScript peudocode may be more helpful in clarifying how Twitter’s algorithmic feed works:
export abstract class TwitterAlgorithmicFeed { /** * Pseudo-code for understanding how Twitter's algorithmic feed works. */ async getAlgorithmicTimelineForUser(user: User): Promise<Timeline> { const rawTimeline = await this.getRawTimelineForUser(user) const relevantTweets = await this.getPotentiallyRelevantTweetsForUser(user) const mergedTimeline = await this.mergeTimelinesForUserBasedOnRelevancy( user, rawTimeline, relevantTweets ) return this.injectAdsForUserIntoTimeline(user, mergedTimeline) } /** * Returns a reverse-chronological stream of tweets from users directly * followed by a given user. */ abstract getRawTimelineForUser(user: User): Promise<Timeline> /** * Returns a stream of tweets ordered by relevancy for a given user at a * given time. * * This will only consider tweets from users the given user is not already * following. */ abstract getPotentiallyRelevantTweetsForUser(user: User): Promise<Timeline> /** * Returns a stream of tweets ordered by relevancy to a given user, taking * into account both their raw timeline of latest tweets and a subset of * the network graph timeline containing potentially relevant tweets. */ abstract mergeTimelinesForUserBasedOnRelevancy( user: User, rawTimeline: Timeline, relevantTweets: Timeline ): Promise<Timeline> /** * Returns a stream of tweets which injects ads into the timeline for a * given user. */ abstract injectAdsForUserIntoTimeline( user: User, timeline: Timeline ): Promise<Timeline> }
Engineering Considerations
Open sourcing aspects of Twitter’s algorithmic feed would inherently run into a few major engineering challenges.


Scale
The first challenge is scale. Twitter’s network graph is massive. The engineering and operational challenges involved in guaranteeing a good user experience tend to outweigh other considerations out of necessity.
To give you an idea of the scale we’re talking about:
- Twitter’s network graph contains hundreds of millions of nodes and billions of edges. (source; 2021)
- Twitter has over 300M worldwide monthly active users. (source; 2019)
- Every second, an average of ~6K tweets are posted and over 6M queries are made to fetch timelines. (source; 2020)
- “Public conversations happening on Twitter typically generate hundreds of millions of Tweets and Retweets every day. This makes Twitter perhaps one of the largest producers of graph-structured data in the world, second perhaps only to the Large Hadron Collider.” (source; 2020)
Simply put, most developers and even most companies aren’t equipped to handle this amount of data in an experimental setting, much less in anything resembling a production setting.
To deal with this challenge, Twitter provides select API partners with a 1% sampled version of their public tweet firehose as well as the ability to listen to smaller subsets of filtered streams.
Additionally, Twitter’s scale introduces some unique challenges when building graph machine learning algorithms because their network graph is forced to be very selective about where they choose to use strong vs eventual consistency. This complicates things since there are no guarantees that every node in the graph has the same features applied to it.
Real-Time
Twitter’s real-time nature presents another unique challenge. Users expect Twitter to be as close to real-time as possible, which means that the underlying network graph is very dynamic and latency becomes a real UX concern. When users refresh their feeds, they expect near instantaneous results that are globally refreshed up-to-the-second. This is incredibly difficult to do efficiently when the underlying network graph is constantly changing.
Temporal Graph Networks are an interesting related open source project from Twitter research. They present a framework for deep learning on highly dynamic graphs which change over time by representing them as sequences of timed events.
Reliability
Another major challenge is platform reliability. Hundreds of millions of people rely on Twitter as a core component of their online digital identity. The engineering and operational challenges inherent in running a global platform like Twitter with a reliably good user experience and Twitter’s uptime expectations are mind boggling.
Security & Privacy
From Rebuilding Twitter’s public API (2020):
“One aspect of the platform that has been top of mind since the beginning is the importance of serving the health of the public conversation and protecting the personal data of people using Twitter.
The new platform takes a strong stance on where related business logic should live by pushing all security and privacy related logic to backend services. The result is that the API layer is agnostic to this logic and privacy decisions are applied uniformly across all of the Twitter clients and the API.
By isolating where these decisions are made, we can limit inconsistent data exposure so that what you see in the iOS app will be the same as what you get from programmatic querying through the API.”

Conclusion (for now)
Hopefully this post has helped you understand how Twitter’s algorithmic feed works, what it’s underlying network graph looks like, and some of the main engineering considerations which make it such a challenging problem to deal with at scale.
Here are some high-level questions that I hope to answer in a follow-up post:
- What would open sourcing the Twitter algorithm actually look like?
- Would it be possible to abstract away all of the engineering complexity that it takes to run a global, production system like Twitter and produce an OSS spec or API that is actually useful?
- Would it be possible to produce meaningful results without access to Twitter’s full data set?
- What does meaningful even mean here? How would we define success?
- What would need to happen in order to make this a reality?
- What are some practical proposals that would help improve the status quo? (since we don’t all have $43B to try and buy Twitter 😂)
If you’re interested in answers to any of these questions, please let me know on twitter.
Further Reading












Follow me on twitter for more vibes @transitive_bs
